Imaginably
various applications within each category can be constructed.
 For
example, a KCM model may be used for investment activities,
such as valuation, risk assessment or imposing a best practice
methodology to the due diligence workflow. The importance
of such a model can be measured by its contribution to the
“expected value” of the investment transaction.
For
example, a KCM model may be used for investment activities,
such as valuation, risk assessment or imposing a best practice
methodology to the due diligence workflow. The importance
of such a model can be measured by its contribution to the
“expected value” of the investment transaction.
There
are already many applications available that directly or indirectly
operating a KCM model. Among them are authoring tools such
as Analytica and Protégé, knowledge bases such
as Xaraya and KnowledgeStorm, and reasoning or analytical
models such as MetaStock or Apoptosis, as well as many strategic
games. Noteworthy, an important aspect of Knowledge Modeling
is the incorporation of users’ subjectivity that is
missing from many current solutions.
Knowledge
Modeling is not the perfect solution for every situation.
But there are many applications that could benefit from KCM,
such as the following situations:
-
The number or complexity of parameters involved in an activity
makes it hard to proceed without risk of overlooks or without
computational aids.
-
The decision-making process is so important and stakes are
so high that one cannot afford making any mistakes. In other
words, when the Cost of Mistake or Value of Certainty is so
high that it justifies the effort.
-
Streamlining and/or continuous improvement of repetitive activities.
-
Preserve and build upon domain expert efforts in house.
-
Capture and package domain knowledge for transfer, share or
sale.
-
Facilitate decision-making by less skilled workers.
-
To automate tasks and/or business processes.
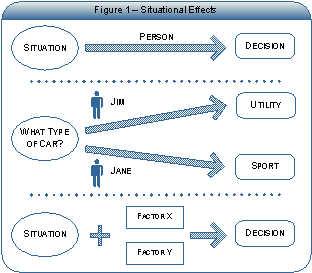
The
below example, Figure 2 – Simplified Decision Mode,
shows a simplified decision model for "buying a used
car.” In this example, both quantitative and qualitative
elements are used in the decision-making process.
4.
Model Types
At
its highest-level, Knowledge Models can be categorized into
following seven groups:
4.1
DIAGNOSTIC MODELS
This
type of model is used for diagnosing problems by categorizing
and framing problems in order to determine the root or possible
cause.
Semantic:
Complaint » Possible Cause(s)
Example:
I have these symptoms. What is the problem?
4.2
EXPLORATIVE MODELS
This
type of model is designed to produce possible options for
a specific case. The options may be generated using techniques
such as Genetic Algorithms or Monte Carlo simulation, or retrieved
from a knowledge and/or case-base system.
Semantic:
Problem Description » Possible Alternatives
Example:
Ok, I know the problem. What are my options?
4.3
SELECTIVE MODELS
This
type of model is used mainly for the decision-making process
in order to assess or select different options. Of course,
there would be always at least two alternatives; otherwise
there is no need for making any decision.
A
Selective Model distinguishes between cardinal and ordinal
results. On one hand, when a cardinal model is used, the magnitude
of the result’s differences is a meaningful quantity.
On the other hand, ordinal models only capture ranking and
not the strength of result. Selective Models can be used for
rational Choice under Uncertainty or Evaluating and Selecting
Alternatives. Such a selection process usually has to consider
and deal with “conflicting objectives.”
Semantic:
Alternatives » Best Option
Example:
Now I know the options. Which one is the best for me?
4.4
ANALYTIC MODELS
Analytical
Models are mainly used for analyzing pre-selected options.
This type of model has the ability to assess suitability,
risk or any other desire fitness attributes. In many applications,
the Analytic Model is a sub-component of the Selective Model.
Semantic:
Option » Fitness
Example:
I picked my option. How good and suitable is it for my objective?
4.5
INSTRUCTIVE MODELS
Instructive
(or Prescriptive) models provide guidance in a bidirectional
or interactive process. Among the examples are many support
solutions available in the market.
Semantic:
Problem Statement » Solution Instruction
Example:
How can I achieve that?
4.6
CONSTRUCTIVE MODELS
A
Constructive Model is able to design or construct the solution,
rather than instructing it. Some of the recently popularized
Constructive Models are used for generating software codes
for various purposes, from computer viruses to interactive
multimedia on websites like MySpace.com.
Semantic:
Problem Statement » Design Solution
Example:
I need a <…> with these specifications <...>.
4.7
HYBRID MODELS
In
many cases more advanced models are constructed by nesting
or chaining several models together. While not always possible,
but – ideally – each model should be designed
and implemented as an independent component. This will allow
for easier maintenance and future expansion. A sophisticated,
full-cycle application may incorporate and utilize all the
above models:
Diagnostic
Model » Explorative Model » Selective Model »
Analytic Model » Constructive Model
5.
Technology Options
As a best practice approach knowledge models should stay implementation
neutral and provide KCM experts with flexibility of picking
the appropriate technology for each specific implementation.
In
general the technology solutions can be categorized into Case-based
systems and knowledge-based systems. Case-based approach focuses
on solving new problems by adapting previously successful
solutions to similar problems and focuses in gathering knowledge
from case histories. To solve a current problem: the problem
is matched against similar historical cases and adjusted accordingly
to specific attributes of new case. As such they don’t
require an explicit knowledge elicitation from experts.
Expert or knowledge-based systems (KBS) on the other hand
focuses on direct knowledge elicitation from experts.
There
are a variety of methods and technologies that can be utilized
in Knowledge Modeling, including some practices with overlapping
features. Highlighted below are the most commonly used methods.
5.1
DECISION TREE & AHP
A
Decision Tree is a graph of options and their possible consequences
used to create a plan in order to reach a common goal. This
approach provides designers with a structured model for capturing
and modeling knowledge appropriate to a concrete-type application.
Closely
related to a Decision Tree, AHP (Analytic Hierarchy Process)
developed by Dr. Thomas Saaty bestows a powerful approach
to Knowledge Modeling by incorporating both qualitative and
quantitative analysis.
5.2
BAYESIAN NETWORKS & ANP
Influence-based
systems such as Bayesian Network (Belief Network) or ANP (Analytic
Network Process) provide an intuitive way to identify and
embody the essential elements, such as decisions, uncertainties,
and objectives in effort to better understand how each one
influence the other.
5.3
ARTIFICIAL NEURAL NETWORK
An
Artificial Neural Network (ANN) is a non-linear mathematical
or computational model for information processing. In most
cases, ANN is an adaptive system that changes its structure
based on external or internal information that flows through
the network. It also addresses issues by adapting previously
successful solutions to similar problems.
5.4
GENETIC & EVOLUTIONARY ALGORITHMS
Inspired
by biological evolution, including inheritance, mutation,
natural selection, and recombination (or crossover), genetic
and evolutionary algorithms are used to discover approximate
solutions that involve optimization and problem searching
in Explorative Models (refer to Model Types).
5.5
EXPERT SYSTEMS
Expert
Systems are the forefathers of capturing and reusing experts’
knowledge, and they typically consist of a set of rules that
analyze information about a specific case. Expert Systems
also provide an analysis of the problem(s). Depending upon
its design, this type of system will produce a result, such
as recommending a course of action for the user to implement
the necessary corrections.
5.6
STATISTICAL MODELS
Statistical
Models are mathematical models developed through the use of
empirical data. Included within this group are 1) simple and/or
multiple linear regression, 2) variance-covariance analysis,
and 3) mixed models.
5.7
RULE ENGINES
Another
effective tool for Knowledge Modeling is a Rule Engine, which
is categorized as an Inference Rule Engine or a Reactive Rule
Engines.
The
Inference Rule Engines is used to answer complex questions
in order to infer possible answers. For example, a Mortgage
Company would ask - "Should this customer be allowed
a loan to buy a house?"
Reactive
Rule Engines are used to detect and react to interesting patterns
of events occurring and reacting.
5.8
WORKFLOW SYSTEMS
A
Workflow System manages the operational aspect of a work procedure,
analyzing 1) how tasks are structured, 2) who performs them,
3) what their relative order is, 4) how they are synchronized,
5) how information flows to support the tasks, and 6) how
tasks are being tracked. Workflow problems can be modeled
and analyzed using graph-based formalisms like Petri nets.
(see Process dimension of knowledge
management)
5.9
OTHER
Other
technologies that can be used in Knowledge Modeling include
the conventional programming approach, and various Knowledge
Management systems. Even simple scripting in Excel could be
used in some KCM applications.
6. Development
Process
During
the implementation process of Knowledge Modeling, four basic
stakeholders are involved throughout the duration of the project,
including the 1) Knowledge Provider, 2) Knowledge Engineer
and/or Analyst, 3) Knowledge System Developer, and 4) Knowledge
User.
Many
Knowledge Modeling projects intertwine a series of sequential
models, which can be nearly identical in design, incorporate
unlike decision values or be radically different. As such,
KCM Experts have to plan, design and model the solution accordingly.
As
a general principle, the following rules must be taken into
consideration:
-
The development process is iterative and will require extensive
supervision.
- Knowledge Models often outlive a particular implementation
procedure – focus first on the conceptual structure
and leave the programming details for later consideration.
- There will be a great demand for extendibility and ongoing
maintenance.
- Errors in a knowledge base or model can cause serious problems
to the project.
- Focus on extendibility, reusability, interoperability, modularity
and maintainability.
- Ideally, KCM models have to closely resemble the human mind
and thought process.
- Expectations have to be carefully managed. KCM is extremely
powerful – not a solution for solving every problem.
- It is very important to ask the right questions, understand
the appropriate breakdowns and consolidate the embedded elements.
The
development process of Knowledge Modeling consists of the
following seven phase:
Phase
1 Goal Setting and Planning
Phase 2 Knowledge Elicitation and Breakdown
Phase 3 Source and/or Proxy Selection and Aggregation
Phase 4 Weight Setting and Profiling
Phase 5 Prototyping and Feasibility Check
Phase 6 Design and Implementation
Phase 7 Monitoring and Maintenance
6.1
GOAL SETTING AND PLANNING
The
Goal Setting and Planning Phase is to identify the project’s
objectives and requirements. Only a clear description will
result in a successful Knowledge Modeling project. Make sure
to sufficiently manage expectations during the requirement
analysis segment.
Diagnose
the objective » Establish goals and determine requirements
What
is to be achieved? What are the User Input and Output requirements?
Generalize as much as possible while keeping the trade-offs
of generalization in check. Make sure that the level of generalization
is acceptable to the User.
At this step in the project, a Knowledge Model should be viewed
as a “blackbox.” A decision should be made as
to the Expected Inputs and Outputs of the model (also referred
to as Direct Input/Output). Depending on the User, the type
of model (including its required interfaces) may vary dramatically.
Some Knowledge Models are used only programmatically, while
others may require human interaction in order to operate.

The
Knowledge Model should not only consider the interpretation
of information, but also consider the consequences of each
decision path and its respective risk sensitivity. The KCM
Expert may have to manage for the uncertainty and quality
of Inputs (or information). In many cases, the level of certainty
is represented as probability in light of their possible consequences.
Furthermore,
take into consideration the fact that the model’s Output
may lead to different courses of action, and the consequence
of such action would determine the value of the Output. In
turn, the Output’s value depends on the problem at hand
and the Output may represent a different value in a separate
application. The first question to ask is “What affect
can the Output have on a decision or activity?
6.2 KNOWLEDGE ELICITATION & BREAKDOWN
The
Knowledge Elicitation and Breakdown Phase focuses on extracting
knowledge from Experts, including high-level input requirements
and processing methods within a structured and formalized
profile. At its basic level, Phase 2 presents an implementation-independent
description of knowledge involved in a given task.
Domain
knowledge elicitation and terminology mismatching present
a challenge during the Knowledge Elicitation and Breakdown
Phase. Asking the right question(s) is the key element to
overcome this challenge.
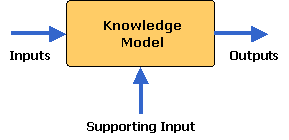
In
most cases, in addition to Direct Inputs, KCM models require
Supporting Inputs in order to produce results. According to
objectives outlined in Phase 1, domain Experts should select
and define the required supporting inputs for the Model. This
supporting information is to be utilized in the model processing
to produce the expected Outputs.
However,
in an ideal situation, KCM models should be designed to operate
independent of Supporting Inputs or uncertainty. To compensate
for this incomplete processing ability, the model’s
Output(s) may include probability, confidence or risk level.
This
phase will include interview with subject matter experts and
other stakeholders to identify supporting inputs required
to generate the outputs and the processing approach. . The
Supporting Inputs typically include tangible and intangible
factors and/or forces affecting the Outputs.
The
interview process should consider the breakdown of Inputs
in order to create sub-models for the purpose of increasing
usability, accuracy and manageability. Referred to as Top
Down Modeling, this approach oftentimes produces the best
results in the interview process.
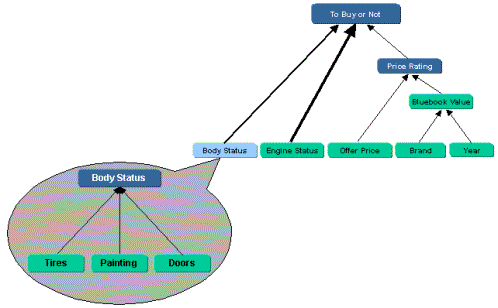
Following
diagram illustrates the breakdown of one of decision elements
in a separate model.
In
the following example, one of the assessment elements is externalized
in a sub-model that can be utilized independently. This approach
empowers Users to monitor, evaluate and eventually replace
sub-components separately by hand-picking equivalent models
from other experts, if desired.
Tips
for Knowledge Elicitation and Breakdown:
-
Focus on and start with top-level most influential Inputs.
- Begin with the minimum number of parameters and gradually
breaking them up in each iteration.
- Even the Inputs with unknown and/or uncertain values have
to be included in the model.
- Take note that some inputs are not known and meaning “we
don’t know that we don’t know them”. Some
implementation alternatives consider this fact,
and include a few unobservable Inputs into Model.
- Keep the number of Inputs to a minimum; however, selecting
the right Inputs is crucial. These Inputs may be nonlinearly-related
and have a very low correlation. Avoid using high correlation
Inputs.
The
most important element in the Knowledge Elicitation and Breakdown
Phase is to correctly and completely define the Inputs and
Outputs. Decision Trees and Influence Diagrams may be of assistance
in this phase. An Influence Diagram is a simple visual representation
of a problem and offer an intuitive way to identify and display
the essential elements, including decisions, uncertainties,
and objectives, and how they influence each other. Mind Mapping
applications present another good tool for capturing information
in a structured format. Among these applications, FreeMind
is one of the best options available.
6.3
SOURCE/PROXY SELECTION & AGGREGATION
During
this Phase, each Input has to be associated with a source
and/or proxy. A proxy source may be considered if a direct
source can not be identified. The underlying objective of
this Phase is to instill modularization and simplification.
Keep
in mind that some Inputs may require the Expert’s personal
judgment about uncertainty, while other Inputs may be retrieved
programmatically from independent sources.
Pay
particular attention to the trade-offs when dealing with uncertainty
or the quality of sources. Depending on the source, trade-offs
can be addressed one of three ways:
1)
Supporting input that will provide the certainly level
2) The model will handle Supporting Inputs internally by assuming
certain probability
3) The model implementation will smoothen the input and classify
it before putting it to use.
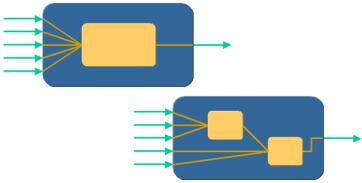
Inputs
have to be analyzed and, if possible, consolidated because
some Inputs may be used in multiple sub-models. Furthermore,
multiple model aggregation may be implemented during Phase
3. Specific applications may benefit by aggregating parallel
models as illustrated in the diagram below. In this example,
both manual and a semi-automated diagnostics sub-model are
aggregated into the main model. Such aggregation could provide
another level of validation for mission critical applications.
6.4 WEIGHT SETTING AND PROFILING
To
capture an Expert’s subjective view, KCM models need
to be enhanced with importance measures or weights of Inputs
as part of the Weight Setting and Profiling Phase. This situation
will allow for future calibrations without any need for model
interface changes (i.e. Input/Output). In order to produce
a superior model for Users, researchers must understand and
represent the User’s objectives as well. As such, KCM
models should support a customizable setting of fitting models
to Expert and User subjectivity, referred to as “Profiling.”
In
general, KCM applications can be personalized in the following
ways:
-
Fixed model, personalized weights
The
same model is used with different weight sets.
-
Fixed weights, personalized model (by dynamic selection of
sub-models)
The
model and its weights are fixed, but the sub-models are selected
based on User preferences.
-
Dynamic mode with personalized weights and model
Both
the model and its weights are customized for the User.
While
the initial weight setting is done during the implementation
process, models should support “profile change.”
This refers to the runtime adjustment of weights according
to the User’s preferences.
For
example, the same analytic model designed to assess the risk
of a transaction may be executed by two distinct Expert profiles
in effort to utilize different assessment opinions.
The
process of obtaining and assigning the importance level of
Inputs is referred to as “Preference Elicitation”
in order to obtain a good and useful description of the preferences
and/or objectives. In general, it is difficult to elicit preferences
and objectives because of the “fuzzy thinking”
nature of the human mind. In many cases, Experts are more
comfortable making qualitative preference statements such
as “I like this more than that.” This type of
ranking (also known as comparative preference elicitation)
is a very useful first step for selecting the weights within
Inputs. In some applications, statistical analysis may be
used for proposing the initial weightings before an Expert’s
review.
6.5
PROTOTYPING AND FEASIBILITY CHECK
The
Prototyping and Feasibility Check Phase introduces a proof
of concept for the proposed model. The purpose of this Phase
is to simulate, link together and test against a limited number
of sample cases related to Inputs and Plans Modules in order
to validate the solution of the problem statement. The result
from such a feasibility check may suggest the iteration of
a previous phase.
In
many cases, a simple spreadsheet or a Decision Tree can provide
enough support for a high-level feasibility analysis. A more
in-depth analysis can be conducted at each sub-model level.
Accuracy
is then measured against the difference between the observations
from known cases verses the model’s Outputs. Deviations
can be represented in standard statistical forms, such as
Mean Squared Error (MSE). The level of acceptable error is
identified through a sensitivity analysis.
Missing
Inputs are by far the most important factors contributing
to such deviations. Thus, the initial step to fix a poor-performing
model is to include revised input selection. Unknowingly,
experts sometimes leverage other freely available Inputs from
the environment or case-based exceptionalities that are hard
to elicit, unless directly asked during the interview process.
Therefore, it is very important to review all discrepancies
from expected Outputs with domain Experts.
Other
common causes of deviations are inappropriate weight settings
and the poor quality of the operator’s quantitative
inputs.
To
avoid dealing with multiple points of failure at the same
time, each potential source of a problem ideally has to be
examined in isolation. Using the same weight setting will
help eliminate one point of failure.
Additionally,
an independent profiling test should be performed to validate
the model by using different profiles from different Experts.
6.6
DESIGN AND IMPLEMENTATION
During
the Design and Implementation Phase, KCM models are designed
and handed over to developers for implementation. Selecting
the right design and technology is the key to a successful
project.
At
some point, models will have to deal with both the quantitative
and qualitative use of Input information in light of their
significance and cost of acquisition. Therefore, the model
design should not only involve technical, but also economical
decisions. Trade-offs between model accuracy, performance
and cost of operation will dictate the design’s requirements.
The
best way to properly manage this situation is choosing the
right use of the Input Processing Mode. Models may be designed
with Parallel or Sequential Input Processing or a combination
of the two. Parallel Input Processing generates maximum performance,
however, it requires all Inputs to be presented at the same
time. Since some of the Inputs are extremely costly or time-consuming
to acquire, Parallel Input Processing may not always be feasible.
Alternatively, a Sequential Input Processing may eliminate
the need of some Inputs, if not applicable to the presented
case – hence saving time and/or money.
Selecting
the right processing model in accordance to the significance
and cost of acquisition for each Input will result to an optimal
design. However, this situation may not be possible because
some Inputs require a specific mode of processing. In the
following diagram, the model leverages both Parallel and Sequential
Input Processing to eliminate unnecessary Input needs.
For
example, in an Investment Selection Model, the Rate of Return
(ROI) may be used initially as a self-sufficient filtering
element to eliminate alternatives with expected ROI below
a certain threshold. But it is also used at a later stage
in conjunction with Risk in the selection process. While both
ROI and Risk by themselves can be used in the elimination
process, neither can be used as standalone indicators in the
selection process.
The
phasing of Input data gathering can be extended to the application
layer. In turn, data gathering may happen in a synchronized
or an asynchronized mode. For instance, a workflow system
could manage the data collection process in an asynchronized
mode and publish the results or notify Users when the Outputs
are available. When no real-time requirements exist, more
complex applications could benefit from such asynchronies
approach in favor of cost saving and load balancing.
At
this juncture, a decision needs to be made as to how to deals
with missing Inputs. While Direct Inputs are usually mandatory,
the Supporting Inputs should be designed as optional. Under
certain circumstances, this obviously may not be possible.
That
can be achieved using:
- Default Value
The
model may use a single or a set of default values to be used
for missing Inputs. Such default values can be calculated
as a statistical average.
Caution:
The use of an average may be of benefit in many applications.
However, in some cases, this approach many result in an undesired
cancel-out effect. As Mark Twain said, “If a man has
one foot in a bucket of ice and the other in a bucket of boiling
water, he is, on the average, very comfortable.”
-
Approximation
A
model may be designed to approximate a value for missing Input
based on internal rules or other presented Inputs.
-
Internal Switch
A
wrapping model may include multiple models and internally
switch to a model designed without any dependency to missing
input.
In
general a model will include four distinct layers, as illustrated
below.The first layer will manage the data transformation.
In many cases, the Input data has to be transformed before
the actual processing can begin. A transformation module will
perform such pre-processing.
The
second layer is to validate the Input data according to the
model’s requirements. Even though validation can be
done at the application level, as a best practice approach,
having a model’s internal data validation is highly
recommended. Then, the actual processing, the third layer,
may begin.
Finally,
the resulting data may require post-processing in order to
be returned to the User or wrapping application.
6.7
MONITORING AND MAINTENANCE
The
Monitoring and Maintenance is an ongoing process throughout
the life of Knowledge Models. The level and sophistication
of human knowledge is constantly increasing and as such the
expectation of Knowledge Models. Unless regularly maintained
and improved, designed models will become obsolete as the
modeled knowledge changes.
At
times, continuous calibration can be designed and performed
in an automated manner, as done in unsupervised learning systems
such as ART-ANN (Adaptive Neural Networks) or cybernetic control
systems. However, regularly monitoring and improvements should
be scheduled in a controlled environment.
7.
Disclaimer
This
paper does not provide investment advice, and should not be
relied on as such nor is it a substitute for investment advice.
The statements and opinions expressed here are solely those
of the author and are not intended to constitute professional
advice. Any reliance upon this shall be at the user's own
risk, without any recourse to the author and his associations.
8.
Author
Pejman
Makhfi is a Silicon Valley technology veteran, serial entrepreneur
and angel investor in the high-tech industry. Pejman has more
than fifteen years of progressive experience in providing
consultancy services and best practices to entrepreneurs,
technology investors, and forward-thinking Startups.
Widely
known as a leader in the field of Business Process Automation
and Knowledge Modeling, Pejman has an extensive background
in the software and financial industries and has been the
key architect for several award-winning industry leaders,
such as FinancialCircuit and Savvion.
Today,
Pejman is the Director of Venture Development at Singularity
Institute, Managing Director of a private
angel group and is a member of Venture Mentoring Team
where he provides assistance and guidance to several early-stage
companies, including Novamente
and Perseptio.
His
background includes executive position at TEN,
a top Silicon Valley technology incubator hosting more than
fifty Start-ups. Pejman managed TEN's R&D as well as advised
clients on the issues and trends affecting early stage and
emerging growth companies. Since its inception, TEN has helped
launch of over sixty Startups, including eBay, iPrint, Xros,
Vertical Networks, Right Works, and Intruvert Networks.
Mr.
Makhfi holds a B.S./M.S. degree in Computer Science from Dortmund
University in Germany and is an internationally licensed Project
Manager (PMP) as well as a certified Lean Six Sigma Black
Belt (SSBB) in continuous business improvement. He has authored
multiple Patents and standards and is an active contributor
to organizations such as "IEEE Neural Networks Society",
"American Association for Artificial Intelligence"
and “American Society for Quality”.
Mr.
Makhfi is the author of numerous articles, including Heptalysis
- The Venture Assessment Framework.
9.
Copyright
This
paper is copyrighted by author, but it may, by the author's
permission, be freely downloaded, translated, printed, copied,
quoted, distributed in any appropriate media providing only
that it not be altered in any way in text or intent and the
author is properly credited.